Preface: This article describes an artificial intelligence snake in python, that creates a neuron model using deep Q network reinforcement learning. There is a also a python program that can test the model. The model can be exported to weights and biases and loaded to STM32 Arduino board. All source codes and circuit diagram are provided.
Press here to see video YouTube video
The snake game: Lets describe the snake game. There is a usually square board of n*n dimension. There is a head of the snake (in python the number 1) and a food occupying one random position (in python the number 3 - the empty positions is number 0). The head is starting at the center of the board. The head can be moved up (0), right (1), down(2) and left(3). If it eat the food then a tail (in python number 2) is added to the snake that follows the head. The snake loose if it hits its tail or the borders of the board. The game is becoming more difficult to play as the tail increase in size. The game is wined if the tail is occupied all the free items of the board.
Playing with AI: Our purpose is to make AI to play the snake game. So in snake.py we define the game using the size variable that specifies the size*size of the board. We created the move procedure that implement one move. We have to design the way that the board is translated to the input of the model. This is done in prepare procedure. The input of the model is consisted from 6 numbers. The 4 first is declaring if each movement is free or not (it hits the tail or borders) using 0 or 1 as values. The other two is declaring if the food is up/down , left/right relative to the head of the snake. Three values are used -1,0,1. The output of the model is 4 values describing the probability of each movement. The movement choosing is the one that have the maximum probability. This approach has the advantage that is independents' from the size of the board and the disadvantage that does not have a global view of the board. In order to have a better view of the board if the full board is inputted to the neural network a huge number of neurons will required as board size increases. A partial solution is to use a smaller window but with limited results. So my conclusion of the best results regarding required neural network is this model. So as it is independents of the size of the board it can be trained using 5*5 size and then used with boards like 100*100!!! The model used, except input and output, uses two hidden layers of 32 neurons each. Results that can be archived is mean snake size of about twice the size of the board. To be more clear with size of 100*100, tail size of about 200 is archived playing more than 17.000 movements without loosing. Also during training and playing it is possible to terminate the game.
The training: The method used here is deep Q network reinforcement learning. In reinforcement learning it learns alone by playing in the beginning randomly and progressively less randomly, as it learns from the scoring that we provide. In this procedure it adjusts its Q values in order to give good results. As we said before it starts to learn playing most of the time randomly. This is specified as exploration parameter. In our case in first round of training is 0.9 and then is becoming 0.5 , 0.3 and finally 0.1. It means that 90%,50%,30% and 10% is playing randomly. In Q learning there are two other parameters the alpha and gamma, which in our case is 0.1 and 0.3. The alpha define the learning rate and the gamma the factor that the next movement affects the current one. In our case we did not give reward to a movement that get closer to the food but it learns from relating the current movement to the next ones that it gets reward later. The rewards are -1 if it looses, 1000 if it eat the food. Initially I used this reward policy. But it get confused when the snake has to go to the food and a tail is it's way. In order to not loose in this case a reward of -100 is given if it goes to the food and hit it's tail. In all other cases it is zero. In training we print statistics to get the progress of training. As opposite to supervised learning the loss is not provides us useful info (except to adjust number of epochs). The program create the model and then train it using the four phases specified. It provides 4 files that it is saved. In our case the files is snake1.keras , snake2.keras , snake3.keras , snake4.keras . The last one has the best trained model. In our case it runs the four phases in 2.5 hours. I use for python development the WSL Ubuntu.
Testing the models: In snakeplay.py we can evaluate a model. After specifying the size, we can load a model and see each movement as it plays with test_model or play with eval_model a batch of 10-100 games for example and see the statistics. In case that compatibility problems exists when loading models downloaded you can recreate them using the training code. One interesting experiment is to load models 1,2,3 to compare the results vs the final 4 one.
Export the model: In order to play the game in the microcontroller we have to export the model in a suitable way that Arduino library can read it. We use the snakeexport.py that is a modified version of the code provided by the author of the MicroFlow Arduino library. Two major modifications are made : In loop of weights and biases the np.array(weights) is replaced by weighs alone. The second change is that the produced file has text ready to be inserted directly in Arduino IDE. After running the code a weights_and_biases.txt is produced.
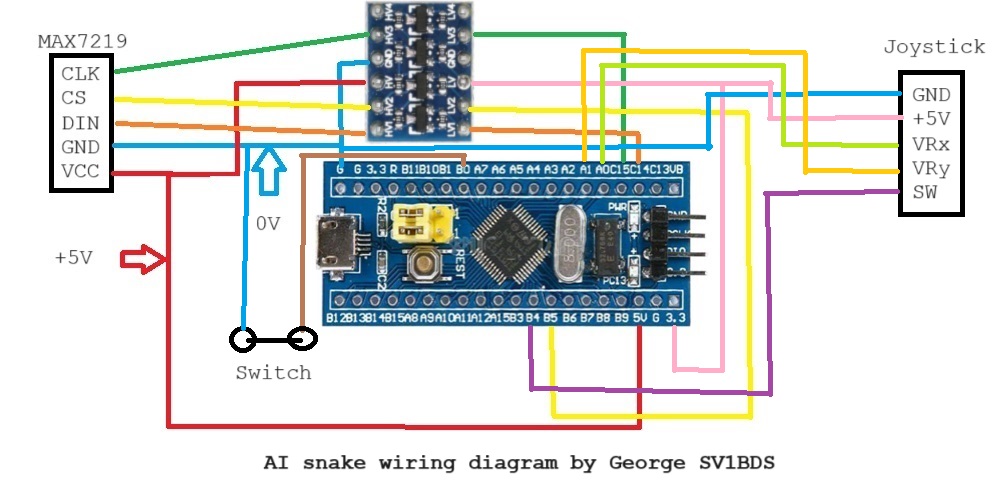
Microcontroller hardware: In order to run the Arduino code we choose the STM32 board also called and blue pill. 328 based solutions does not have enough memory to load the model. A MAX7219 8*8 Led grid board and an analog joystick used. A 3.3 to 5V adapter board also used as MAX7219 is a 5V and STM32 is a 3.3V one. Please note that 5V so called input of joystick is wired to 3.3V!!! Input voltage 5V can be entered via USB or directly. Please take care not in any case give more voltage than 5V!!! In the video I initially take 3.3V from a separate source but as draw current is low internal source can be used.
Arduino software: This is the snakestm32.ino software. The switch at B0 defines if movements are from the user or the AI algorithm. When grounded AI is playing. This can be changed at any time permitting switching between AI and human inside the game. A queue implementation exists as C++ does not have. The model is loaded and called in order to give the proper movement. The user has to press the button of the joystick to start the game. The practically variable time of time passing before pressing the joystick button is used to set the random seed. The MicroFlow library has been modified and for MicroFlow.h and MicroFlow.cpp SOFTMAX support has added. Except MicroFlow a MAX7219 library is used. The SPI used is software as hardware seems not supported in STM32.